此楼介绍外置手册的用法
外置手册
本次更新一个主要功能就是添加自定义添加手册的功能。一方面随着手册的增加,插件的体积会不断增大,使得插件本身变得臃肿,同时将数据和界面分离,方便后期维护;另一方面个人精力、资源都有限,无法满足所有人需求,增加这个功能,大家可以一起维护。
闲话少说,下面进入正题
以下均以外置手册Java为例
下载地址 提取码yfh7
配置格式
增加外置手册需要填写的参数如下图所示
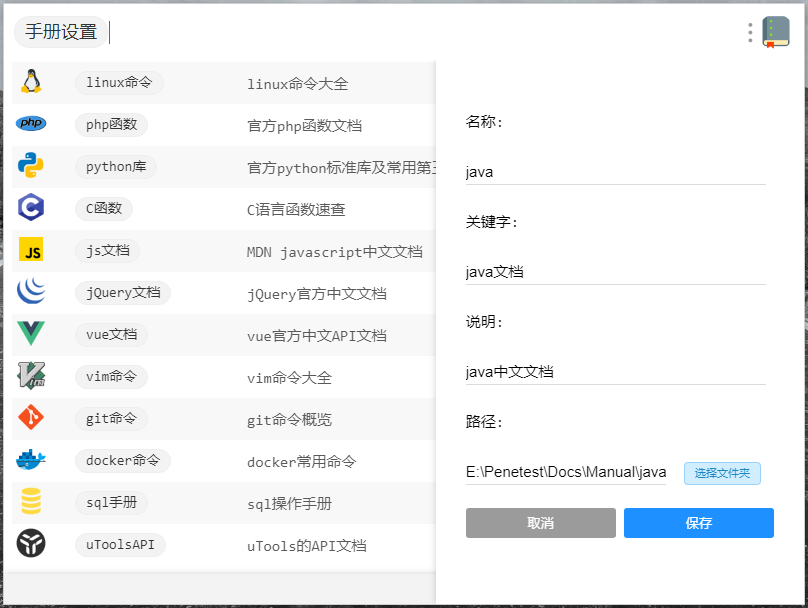
名称是这个手册的唯一标识,类似于uTools插件开发中的code,手册中的大部分配置文件都以此命名,建议以语言的英文名称命名(如果不和已有的内置手册冲突的话)关键字是进入手册的关键词,多个以逗号隔开说明手册描述路径手册所在路径
手册格式
外置手册所在目录内应具备如下几个文件
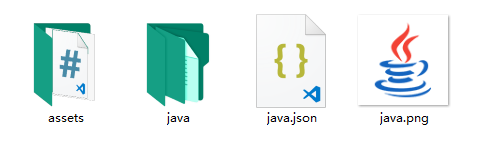
可以看到,所有文件的名称几乎都是以之前配置中的名称命名的
- xxx.json 必须具备的文件,是整个手册的目录文件
- xxx文件夹 必须具备的文件,整个手册的主体就在这个文件夹里了
- xxx.png 非必备文件,在配置页面显示手册的图标,本来也作为这个手册在
uTools主输入框的logo文件,但遗憾的是貌似uTools的logo文件不支持绝对路径,希望官方能够解决一下~
- assets 非必备文件,如需自定义CSS,可以将所有CSS文件放入此中
手册文件夹
手册文件夹内包含了所有手册的文件,获取途径不外乎有两种
import requests
from bs4 import BeautifulSoup
import os
import sys
for i in range(1,28):
url = "https://blog.fondme.cn/apidoc/jdk-1.8-google/index-files/index-%d.html"%i
r=requests.get(url).content
soup = BeautifulSoup(r).select('dt')
for n, x in enumerate(soup):
path = x.a.attrs['href']
if '#' not in path:
file = path[3:]
url = "https://blog.fondme.cn/apidoc/jdk-1.8-google/index-files/" + path
r = requests.get(url).content
sou = BeautifulSoup(r).select('.header,.contentContainer')
d = os.path.dirname(file)
if not os.path.exists(d):
os.makedirs(d)
with open(file, 'w') as f:
f.write(str(sou[0])+str(sou[1]))
sys.stdout.write('\r[%d/%d/%d] %s done!'%(n, len(soup), i, file))
当然,你还可以使用网站镜像的软件或者wget进行递归下载,但是个人还是比较建议使用爬虫脚本,如果你仔细看了脚本的话,会发现这段代码
sou = BeautifulSoup(r).select('.header,.contentContainer')
即在爬取网页时,只爬取了文档的主体内容,一些无关的内容(如侧栏、底栏等)没进行爬取,这样可以节省uTools这种小窗口的空间,同时整个手册也更加整洁。
值得注意的是,<head>标签内的内容也没爬取,因为在插件中内置了一个通用的css样式,如果效果不理想,你可以在外置手册目录中再额外放置一个css文件即可,并且无须在每个文档的html文件中引入,会通过插件自动加载
目录文件
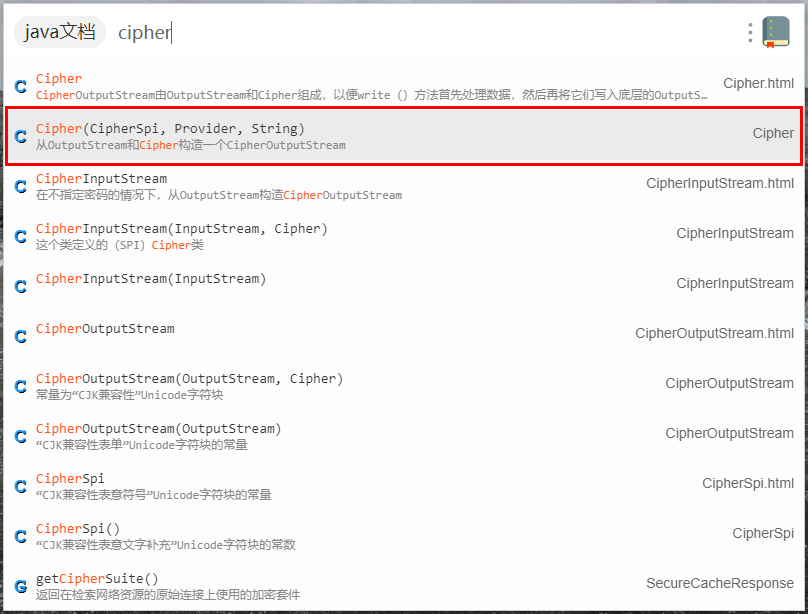
目录文件是数组格式的json文件,数组的每一个值对应着一个函数、目录或者文档,如
{
"name": "Cipher(CipherSpi, Provider, String)",
"type": "Cipher",
"path": "java/javax/crypto/Cipher.html#Cipher-javax.crypto.CipherSpi-java.security.Provider-java.lang.String-",
"desc": "从OutputStream和Cipher构造一个CipherOutputStream"
}
各个键值对应如下,其中type和desc可以留空
生成目录文件
生成目录文件一样需要使用脚本,同样以https://blog.fondme.cn/apidoc/jdk-1.8-google](https://blog.fondme.cn/apidoc/jdk-1.8-google)的java文档为例
import codecs
import requests
from bs4 import BeautifulSoup
import os
import sys
j = codecs.open('java.json', 'a' ,encoding='utf-8')
j.write("[")
for i in range(1,28):
url = "https://blog.fondme.cn/apidoc/jdk-1.8-google/index-files/index-%d.html"%i
r=requests.get(url).content
soup = BeautifulSoup(r).select('dt')
soup2 = BeautifulSoup(r).select('dd')
for x,y in zip(soup,soup2):
name = x.a.text
path = 'java' + x.a.attrs['href'][2:]
type = x.a.attrs['href'].split('/')[-1].split('.html#')[0]
desc = y.text.replace('\n','').replace('"','"')
j.write('{"name":"%s","type":"%s","path":"%s","desc":"%s"},'%(name,type,path,desc))
sys.stdout.write('\r[%d/%d/%d] %s done!'%(soup.index(x), len(soup), i, name))
j.write("]")
j.close()
关于DASH、ZEAL
!!由于增加了devdocs的在线文档和调用dash的功能,以下方法已经意义不大,仅供参考
dash或zeal的离线文档目录一般在Resources文件夹下,这个文件夹内以下几个文件值得关注:
- Documents 文档主体
- docSet.dsidx
sqlite3格式的目录文件
- Tokens.xml
xml格式的目录文件
Tokens.xml文件不是每个文档都有,当有Tokens.xml文件时,使用以下nodejs脚本将其转成本插件可用的目录文件
const fs = require('fs');
xml2Json = (input, output) => {
fs.readFile(input, 'utf8', (err, data) => {
data = data.replace(/\"/g, """);
data = data.replace(/<Token>.*?<Name>(.*?)<\/Name><Type>(.*?)<\/Type>.*?<Path>(.*?>)*(.*?)<\/Path>\s+.*?<\/Token>/g, `{"name":"$1","type":"$2","path":"$4"},`);
data = data.replace(/<\?xml.*?>\s+<Tokens.*?>([\s|\S]*?),\s+<\/Tokens>/, '[$1]');
fs.writeFile(output, data, 'utf8', err => {
err && console.log(err);
})
})
}
xml2Json('Tokens.xml', 'xxx.json')
当没有Tokens.xml文件时,使用以下nodejs脚本将docSet.dsidx转换为本插件可用的目录文件
const sqlite3 = require('sqlite3');
const fs = require('fs');
sqlite2Json = (input, output) => {
let db = new sqlite3.Database(input);
var json = {}
db.all(`SELECT * FROM searchIndex`, function (err, data) {
if (err) {
console.log(err);
return;
}
for (var d of data) {
json[d.name] = d
}
fs.writeFile(output, JSON.stringify(json), err => {
err && console.log(err);
})
})
}
sqlite2Json('docSet.dsidx', 'xxx.json')
需要先安装sqlite3模块
npm i sqlite3